Ceph Cluster rebalance issue
· 5 min readThis is rough draft that I’m just pushing out as it might be useful to someone not stay in my drafts folder forever… Good enough beats Perfect that never ships every time.
I think I have mentioned my ProxMox/Ceph combo cluster in an earlier post. A quick summary is it consists of a five (5) node cluster for ProxMox HA and three of those nodes have Ceph with three (3) OSDs each for a total of nine (9) 5Tb OSDs. They are in a 3/2 ceph configuration with three copies of each piece of data allowing for running if two nodes are active. Those OSD / hard drives have been added in batches of three (3) with one added on each node as I could get drives cleaned and available. So I added them piece meal in a sets of three OSDs, then three more and finally the last batch of three. I’m also committing the sin of not using 10Gbps SAN networking for the Ceph cluster and using 1Gbps so performance is impacted.
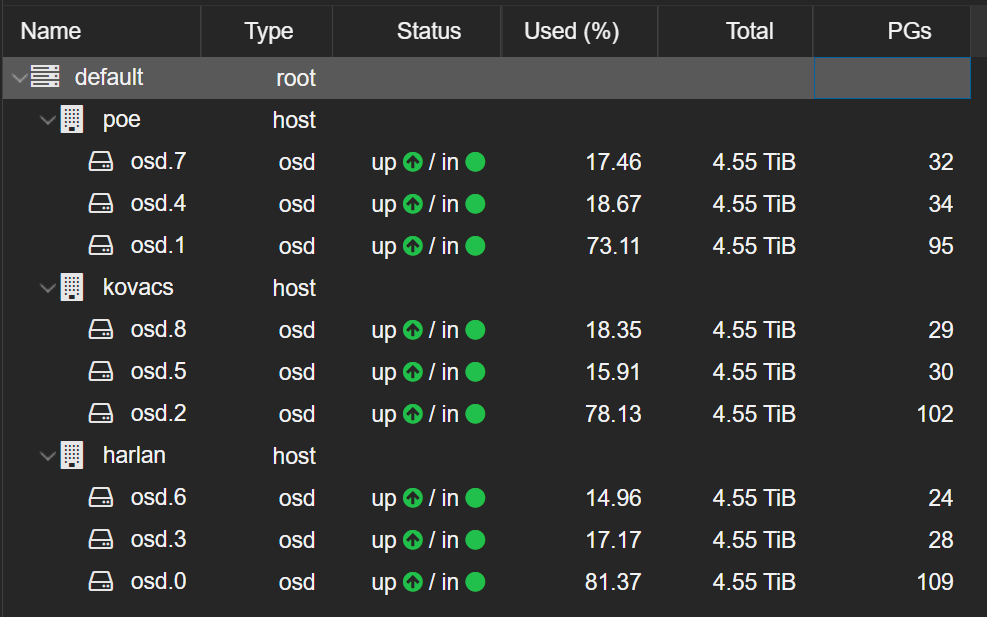
Adding them in pieces as I also loaded up the CephFS with media content is what is hurting me now. My first three OSDs that are spread across the three nodes are pretty full at 75-85% and as I added the next batches, the cluster has never fully caught up and rebalanced the initial contents. This impacts the results of my ‘ceph osd df tree’ results showing I have less space then I actually have available.
Something that I’m navigating is Ceph will go into read-only mode when you approach the fill limits which is typically 95% of space available. It starts alerting like crazy at 85% filled with warning of dire things coming. Notice in my OSD status below that I have massive imbalances between the initial OSDs 0,1,2 versus 3,4,5 and 6,7,8.
ProxMox 8.1 with Ceph Reef by default has the Balancer feature enabled. It is also setup to protect the accessibility of the cluster contents against overuse from rebalancing and recovery activities. In my case, I want the cluster to be less responsive so I can get this rebalanced faster. Often rebalancing and recovery go hand-in-hand but my case only has rebalancing.
How to get default values for Recovery Settings
# ceph-conf --show-config | egrep "osd_recovery_max_active|osd_recovery_op_priority"
osd_recovery_max_active = 0
osd_recovery_max_active_hdd = 3
osd_recovery_max_active_ssd = 10
osd_recovery_op_priority = 3
How to get default values for Backfill Settings
# ceph-conf --show-config | egrep "osd_max_backfills"
osd_max_backfills = 1
Moving those above values up too high can cause OSDs to become overburdened and they could just restart to protect the cluster so you should take it in steps when changing these to higher values. Restart of an OSD from overburden activities may actually cause the recovery or rebalance to take longer so monitor for issues when making these changes.
# ceph tell 'osd.*' injectargs --osd-max-backfills=3
osd.0: {}
osd.0: osd_max_backfills = '3'
osd.1: {}
osd.1: osd_max_backfills = '3'
osd.2: {}
osd.2: osd_max_backfills = '3'
...
# ceph daemon osd.2 config get osd_max_backfills
{
"osd_max_backfills": "3"
}
root@kovacs:~# ceph tell 'osd.*' injectargs --osd-max-backfills=5
osd.0: {}
osd.0: osd_max_backfills = '5'
osd.1: {}
osd.1: osd_max_backfills = '5'
osd.2: {}
osd.2: osd_max_backfills = '5'
...
root@kovacs:~# ceph tell 'osd.*' injectargs --osd-max-backfills=7
osd.0: {}
osd.0: osd_max_backfills = '7'
osd.1: {}
osd.1: osd_max_backfills = '7'
osd.2: {}
osd.2: osd_max_backfills = '7'
...
Bumped up the Recovery Max for both HDD and SSD
root@kovacs:~# ceph tell 'osd.*' injectargs --osd-max-backfills=7 --osd_recovery_max_active=10
osd.0: {}
osd.0: osd_recovery_max_active = '10'
osd.1: {}
osd.1: osd_recovery_max_active = '10'
osd.2: {}
osd.2: osd_recovery_max_active = '10'
...
I considered turning off the Ceph Balancer and manually setting an OSD remapping script. This is my setup for doing that operation but I ended up not using it. I may revisit this once my cluster is balanced to double check if it is as good as it can be.
root@harlan:~/rebalance# ceph balancer status
{
"active": true,
"last_optimize_duration": "0:00:00.000192",
"last_optimize_started": "Mon Feb 12 16:27:16 2024",
"mode": "upmap",
"no_optimization_needed": false,
"optimize_result": "Too many objects (0.184387 > 0.050000) are misplaced; try again later",
"plans": []
}
root@harlan:~/rebalance# ceph balancer off
[did not execute above line]
root@harlan:~/rebalance# ceph osd getmap -o om
got osdmap epoch 11734
root@harlan:~/rebalance# osdmaptool om --upmap ./upmap.sh --upmap-pool cephfs_data --upmap-deviation 1 --upmap-max 20
osdmaptool: osdmap file 'om'
writing upmap command output to: ./upmap.sh
checking for upmap cleanups
upmap, max-count 20, max deviation 1
limiting to pools cephfs_data ([2])
pools cephfs_data
prepared 10/20 changes
root@harlan:~/rebalance# bash ./upmap.sh
[did not execute above line]
When we are done I need to change back to the defaults in each OSD
ceph tell 'osd.*' injectargs --osd-max-backfills=1 --osd_recovery_max_active=0
Turn back on the Balancer (if I turn it off which I did not)
root@harlan:~/rebalance# ceph balancer on
Turn back on scrubbing and deep-scrubbing
ceph osd unset noscrub
ceph osd unset nodeep-scrub
This appears to have accelerated my recovery time and the above mess of commands and attempts may help someone someday.
References
Here is a reference of things I read or found that seemed to be useful.
Getting config values from OSD
These can only happen on the node that has the OSD.
ceph daemon osd.<insert_id> config get osd_max_backfills
root@kovacs:~# ceph daemon osd.2 config get osd_max_backfills
{
"osd_max_backfills": "5"
}
Turned off Scrubbing and Deep Scrubbing on the Cluster
You can disable deep and regular scrubbing but it will cost you later in catchup after the balancing is finished.
__noscrub,nodeep-scrub flag(s) set__
This might help with the utilization of the disk bandwidth and I did it out of desperation.
# ceph osd set noscrub
# ceph osd set nodeep-scrub
Well worth reading and referencing
Copied from TheJJ… and worth a read for anybody digging into Ceph. My fork of TheJMM Ceph Cheatsheet which you can also go to the original at Ceph Cheatsheet.
This article How to monitor Ceph: the top 5 metrics to watch was one of the better ones on figuring out what was happening in my ceph cluster.