This is rough draft that I’m just pushing out as it might be useful to someone not stay in my drafts folder forever… Good enough beats Perfect that never ships every time.
I think I have mentioned my ProxMox/Ceph combo cluster in an earlier post. A quick summary is it consists of a five (5) node cluster for ProxMox HA and three of those nodes have Ceph with three (3) OSDs each for a total of nine (9) 5Tb OSDs. They are in a 3/2 ceph configuration with three copies of each piece of data allowing for running if two nodes are active. Those OSD / hard drives have been added in batches of three (3) with one added on each node as I could get drives cleaned and available. So I added them piece meal in a sets of three OSDs, then three more and finally the last batch of three. I’m also committing the sin of not using 10Gbps SAN networking for the Ceph cluster and using 1Gbps so performance is impacted.
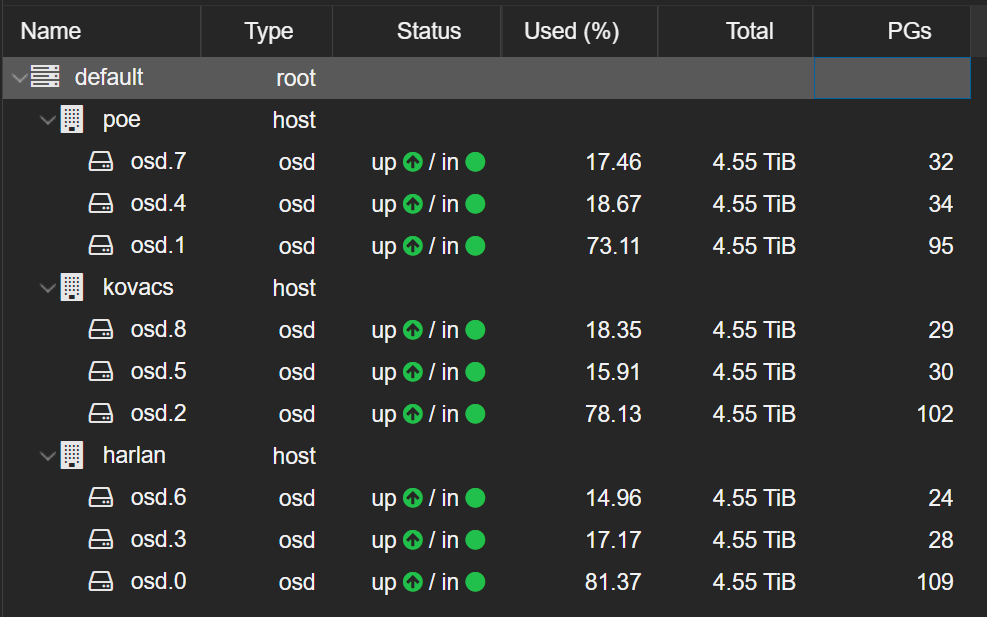
Adding them in pieces as I also loaded up the CephFS with media content is what is hurting me now. My first three OSDs that are spread across the three nodes are pretty full at 75-85% and as I added the next batches, the cluster has never fully caught up and rebalanced the initial contents. This impacts the results of my ‘ceph osd df tree’ results showing I have less space then I actually have available.
Something that I’m navigating is Ceph will go into read-only mode when you approach the fill limits which is typically 95% of space available. It starts alerting like crazy at 85% filled with warning of dire things coming. Notice in my OSD status below that I have massive imbalances between the initial OSDs 0,1,2 versus 3,4,5 and 6,7,8.